背景知识
1. CV 领域的掩码生成(Masked Generation in Computer Vision)
- 在计算机视觉中,掩码生成是一种自监督学习策略,核心思想是:
遮蔽输入图像的一部分,让模型预测被遮蔽区域的内容。 - 代表性工作:
- MAE(Masked AutoEncoder):将图像划分成 patch(如 ViT 中一样),随机遮挡大比例的 patch(如 75%),再让编码器和解码器协作重建这些被遮挡的区域。
- SimMIM、BEiT:也采用类似方式,鼓励模型学习图像的结构性知识。
- 优势:
- 利用了大量无标签图像数据;
- 学到的是更泛化的表示(representation),不依赖具体分类标签。
2. 指数移动平均:动量缓慢更新参数(Momentum Update with EMA)
- 在很多自监督方法中(如 MoCo、BYOL、DINO),会用两个网络:
- 一个是在线网络(online):持续更新。
- 一个是目标网络(target):缓慢更新,用于生成稳定目标。
- 指数移动平均(EMA)公式:
θtarget←m⋅θtarget+(1−m)⋅θonline\theta_{\text{target}} \leftarrow m \cdot \theta_{\text{target}} + (1 - m) \cdot \theta_{\text{online}}θtarget←m⋅θtarget+(1−m)⋅θonline- 其中 m∈[0,1)m \in [0, 1)m∈[0,1) 是动量系数,通常设置接近于1(如 0.99、0.999)。
- 意义:
- 提供一个更加稳定的目标(target)用于对比、对齐或重建。
- 避免模型陷入不稳定的自增强循环。
- JEPA 中作用:student encoder 和 target encoder 使用 EMA 来更新,避免训练过程震荡。
3. Attentive Probe:冻结主干,只训练轻量网络
- Attentive Probe 或 Linear Probe:
- 在预训练之后,不更新主干网络(如 ViT Encoder),只在其输出后添加一个小网络用于特定任务(如分类、回归等)。
- 训练的是新加的小网络,而不是整个模型。
- 常见设置:
- Linear probe:使用一个线性层作为 probe;
- Attentive probe:使用注意力结构(Attention)作为 probe,能够对不同区域给予不同的关注。
- 优点:
- 检验主干网络学到的特征是否具有通用性和可转移性;
- 可以更快训练,避免过拟合。
- 在 JEPA 中的应用:JEPA 表示是对潜在能量进行建模的,使用 probe 网络来评估不同 patch 或视频片段之间的兼容性。
4. ViT(Vision Transformer)简介
- ViT 架构简要介绍:
- 将图像划分成固定大小的 patch(如 16x16);
- 每个 patch 被展平并嵌入为一个向量,形成 patch embeddings;
- 加上 positional encoding 之后,输入 transformer encoder 进行处理;
- 最终通过 [CLS] token 预测分类结果或输出表示。
- Transformer 核心机制:
- Self-Attention:允许模型对所有 patch 建立全局依赖;
- 多头机制(Multi-head Attention):增强模型对不同关系的建模能力。
- 优势:
- 结构统一,方便扩展;
- 可自然迁移到文本、视频、多模态任务。
- 在 JEPA 中的角色:
- ViT 是 JEPA 的视觉编码主干;
- JEPA 将 ViT 作为 encoder,然后通过能量模型进行表示预测,而不是 reconstruct 图像或做分类。
以下是针对你这张图(概率模型、能量模型、潜变量能量模型)整理的背景知识讲稿,适合作为介绍 JEPA 背后的建模范式转变的第二部分内容,标题可为「从概率模型到能量模型:引入潜变量的动机与方法」。
从概率模型到能量模型:引入潜变量的建模动机(讲稿草案)
1. 概率模型(Probabilistic Models)
- 在传统监督学习中,我们通常希望建模一个条件概率分布:
- p(y|x) = \frac{\exp(s(x, y))}{\sum\_{y'} \exp(s(x, y'))}
- 问题所在:
- 归一化分母需要枚举所有可能的 yy;
- 对于离散结构预测(如图像生成、视频推理、多模态任务)来说,这种枚举非常昂贵;
- 目标是“生成正确答案”,但本质上我们更关心的是“找到最优答案”。
2. 能量模型(Energy-Based Models, EBM)
- 能量模型摒弃了显式归一化,转而定义一个能量函数 E(x,y)E(x, y),表示:
- xx 与 yy 配对的兼容性程度(能量越小表示越合理);
- 不需要归一化,只需要比较候选项的能量大小。
- 训练目标(对比学习):
E(x,y+)<E(x,y−)E(x, y^+) < E(x, y^-)- y+y^+ 是正样本,y−y^- 是负样本;
- 用 margin loss 或 softplus 形式实现;
- 优势:
- 无需对全空间做归一化;
- 更灵活,适合结构化预测、多模态生成。
3. 潜变量能量模型
-
在很多任务中,xx 和 yy 的关系并不直接,而是存在一些中间的、未观察到的隐变量 z
-
潜变量的作用:
-
- 表示x 与 y 之间未显式建模的结构信息;
- 可以是“动作意图”、“风格因子”、“视角变化”、“未来轨迹的潜在方案”等;
- 提供一个“解释”的桥梁,使模型更灵活、泛化更强。
-
训练方式:
- 推断 z:通常使用另一个网络或采样策略;
- 联合优化 x, y, z 三者的能量;
- 可结合对比学习。
4. 如何理解潜在变量
- 类比方式:
- x:你看到的一张图片
- y:你想预测的另一个视角、问题答案或未来状态
- z:你没看到的某些关键信息(如该物体的完整三维结构)
- 潜变量可以看作:
- 隐藏的解释因子
- 数据之间不确定关系的补充表示
- 可被学习的桥梁变量,帮助模型建构兼容性或依赖结构
如何理解潜在变量呢?
使得模型可以表示多个预测,需要latent变量,是一个输入变量,不能被观察,但是被推断的,被用于表示y中的信息,但是没办法从x中获取。
举个例子:
如果 x 是一辆汽车驶向岔路口的图片,而 y 是几秒钟后同一辆车在岔路口的一个分支上的图片,可能不知道我前面的司机是左转还是右转、加速还是刹车,但我可以用潜在变量来表示这些选项,这种潜在变量包含了所有对预测有用的信息。
通往AGI的道路
在构建具备“自主智能”的系统时,我们希望 AI 不只是反应输入,还能感知、记忆、预测、规划、执行。图中这套架构反映了这种理想的六模块组成:
1. Configurator(配置器)
- 功能:统筹协调整个系统模块,以适应当前任务。
- 理解方式:就像大脑中的“指挥中枢”,根据任务目标激活合适的处理流程,例如选择哪个感知特征要注意,哪种行为模型要启用。
2. Perception(感知模块)
- 功能:从原始感官输入(如图像、视频)中提取当前世界状态,构建多层次的状态表示。
- 特点:
- 输出可以是位置、速度、关系图等;
- 支持分层抽象,例如 pixel-level、object-level、scene-level;
- 类比:像视觉皮层和认知皮层,负责“看到”和“理解”。
3. World Model(世界模型)
- 功能:
- 补全当前缺失的信息(例如被遮挡的目标);
- 预测未来状态演化(如果我这么做,世界将会怎样?)。
- 核心思想:
- 构建一个“可以在脑中运行的物理模拟器”;
- 类似于人的想象力:提前预演未来,做出更好的决策。
4. Cost Module(代价评估器)
- Intrinsic Cost(本能代价):
- 衡量当前状态是否令人“痛苦”或“愉快”,如危险、能耗、偏离目标等;
- 固定规则定义,不可训练。
- Critic Cost(评价器):
- 预测未来状态可能导致的总成本;
- 通常由模型学习,类似于强化学习中的价值函数(Critic)。
5. STM(Short-Term Memory,短期记忆)
- 功能:
- 存储并回放世界模型的预测轨迹;
- 记录“过去状态 → 未来预测 → 结果反馈”的序列。
- 意义:
- 实现持续性认知与因果推理;
- 与 Transformer 的 cache 概念也有点类似。
6. Actor(执行器)
- 功能:
- 基于世界模型和代价函数,选择一条动作序列(或策略);
- 执行第一个动作,进入下一个感知-预测循环。
- 机制:
- 通常通过优化未来成本来寻找最优动作序列(如 CEM、MPC、强化学习)。
JEPA架构
JEPA 不是生成式的,因为它不能轻易地用于从 x 预测 y。 它仅捕获 x 和 y 之间的依赖关系,而不明确生成 y 的预测。
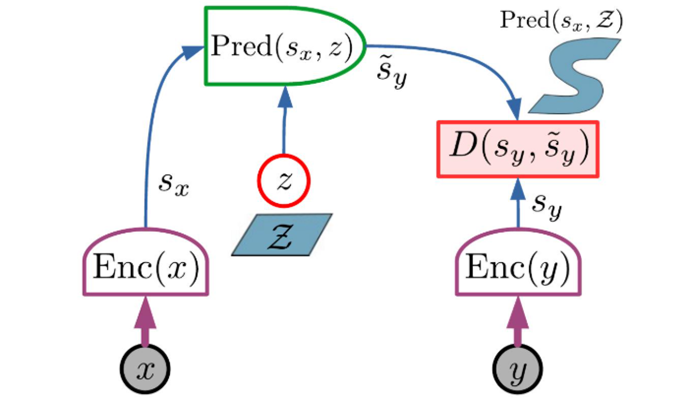
JEPA 的主要优点是它在表示空间中执行预测 ,无需预测 y 的每个细节。
两个变量 x 和 y 被馈送到两个编码器,产生两个表示 sx 和 sy,两个编码器可以不同。这允许 x 和 y 在性质上不同(例如视频和音频)。 预测器模块根据 x 的表示来预测 y 的表示。 预测变量可能取决于潜在变量 z。 能量只是表示空间中的预测误差:。
JEPA 的主要优点是它在表示空间中执行预测 ,无需预测 y 的每个细节。
但是 JEPA 有两种方式可以表示与 x 兼容的 y 值的多重性。 第一个是 y 编码器的不变性,第二个是潜在变量 z
- 编码器函数 sy = Enc(y) 可能具有不变性。 如果一组中的所有 y 都映射到相同的 sy 值,则所有这些 y 将具有相同的能量。 使用 JEPA,我们失去了生成输出的能力,但我们获得了一种强大的方法来表示输入和输出之间的多模态依赖关系
- 通过潜在变量
I-JEPA / V-JEPA
meta提出。
联合的嵌入预测架构

V-JEPA 2: 自监督的世界模型
如何让模型理解世界,并且通过观察来采取行动?
自监督的方式?大规模的互联网视频和少量交互数据(机器人的运动轨迹)
预训练(联合嵌入预测架构-V-JEPA 2)理解能力
用V-JEPA2和大语言模型对齐,进行视频问答任务达到了最佳性能
利用少量的未标记的机器人视频,对V-JEPA2 AC进行后训练,将自监督学习应用于机器人的规划任务。
最后部署到机械臂,使用带有图像目标的规划来实现物体的拾取和放置(零样本)。
在预训练后,利用 V-JEPA 2 模型,获得一个潜在世界模型,该模型可以通过闭环模型预测控制来控制具身智能系统。
AI通过观察行动来理解世界。提出一种自监督的方式,将互联网视频和少量交互数据
(机器人轨迹)结合,开发能在物理世界中理解、预测和规划的模型。
通过100万小时互联网视频数据,预先训练一个embedding-predictive联合架构的V-JEPA 2,这是action-free的。
这个V-JEPA 2模型,在运动理解()和人类行动预期()数据集上实现了很好的效果。
和大语言模型结合后,在视频提问任务上,取得最先进的性能。
如何通过自监督训练引用到机器人规划任务上(通过少于62小时的机器人视频),通过后训练一个latent action-conditioned world model
在V-JEPA框架的基础上,探索更大的模型,增加了预循环数据的大小,并引入了空间和时间的渐进分辨率训练策略,从而扩展了V-JEPA框架。
预训练数据的处理方式
预训练的V-JEPA 2模型可以预测视频中缺少的部分,但是没有考虑agent后续的行动。因此采用了少量交互数据让模型制定计划。
Action-Conditioned World Model 训练
我们的目标是在预训练后采用V-JEPA 2模型,并获得潜在的世界模型,该模型可通过闭环模型预测性控制使用,该模型可用于控制agent系统。
训练一个V-JEPA 2-AC,这是一个自回归模型,预测以控制动作和本体感受为观察条件的未来视频观察表示。
rollout loss和teacher forcing loss
非常好的问题!这实际上涉及目标空间(target space)的结构假设、数据模态的统计特性,以及 训练目标对感知质量与梯度稳定性的权衡。下面我会从 理论动机、实践影响和具体模型差异 三个层面,解释为什么:
V-JEPA 2 用的是 L1 loss,而 I-JEPA 用的是 L2 loss。
🔍 1. 理论动机:L1 vs. L2 的性质差异
| 项目 | L1 Loss (∣∣x−x^∣∣1||x - \hat{x}||_1**∣∣x−x^∣∣1**) | L2 Loss (∣∣x−x^∣∣22||x - \hat{x}||_2^2**∣∣x−x^∣∣22**) |
|--------------|--------------------------------------------------|--------------------------------------------------|
| 对误差敏感性 | 对异常值更鲁棒(绝对误差) | 更惩罚大误差(平方项放大 outlier) |
| 梯度行为 | 常数梯度,训练更稳定 | 梯度随误差增长而增长,可能更不稳定 |
| 最优解含义 | 对应于条件中位数估计(更“平均”) | 对应于条件均值估计(更“精确”) |
| 视觉感知 | 更好保持边缘和结构信息 | 更易导致平滑、模糊化 |
🎥 2. 在图像(I-JEPA)中使用 L2
- 图像表示天然是高斯结构假设下的空间,L2 作为高斯分布最大似然的损失,更符合像素/patch 表示学习的统计特征;
- 在图像 patch 的表示空间中,嵌入是 dense 且连续的,偏离平均值的 patch 更有代表性;
- 所以 I-JEPA 使用 L2,对高斯性质的 patch embedding 拟合是自然选择。
🎬 3. 在视频(V-JEPA 2)中使用 L1
- 视频预测(尤其是未来帧)天然具有多模态性与高度不确定性:
- 未来可能存在多个合法轨迹、多个模糊预测;
- 如果使用 L2,模型可能倾向于“平均”所有可能情况,从而生成模糊表示;
- 使用 L1 的原因:
- 更鲁棒:在存在多个预测解的情况下,L1 更能维持清晰结构;
- 保边缘性与稀疏性:视频场景中目标边缘、光流边界等更容易通过 L1 保留;
- 实验发现 L1 loss 对时间预测任务表现更好(见 V-JEPA 2 ablation)。
损失函数和能量函数的关系:损失函数是由能量函数构成的。
V-JEPA2 采用了一种渐进式训练策略,旨在提高模型的性能并扩展其能力。该策略的核心思想是在训练过程中逐步增加输入视频的时间和空间分辨率,从而使模型能够学习更复杂的视频结构和动态。
渐进式训练的具体步骤如下:
- 暖身阶段: 使用较短的视频片段(16 帧)和较低的空间分辨率(256x256)进行训练,并采用线性学习率暖身策略。
- 恒定阶段: 使用恒定学习率对模型进行训练,直到性能在下游任务上达到平台期。[39]
- 冷却阶段: 在恒定阶段之后,逐步增加视频片段的长度(最多 64 帧)和空间分辨率(最高 512x512),同时线性衰减学习率。此阶段的目标是让模型适应更高分辨率和更长时间的视频输入。[39-40][150]
渐进式训练带来的提升:
- 更强大的视觉理解能力: 通过逐步增加视频长度,模型能够学习更复杂的运动和交互模式,从而在运动理解和外观识别等任务上取得更好的性能。[90]
- 更丰富的视频表征: 通过逐步增加空间分辨率,模型能够学习更精细的视觉特征,从而在图像分类、视频问答等任务上取得更好的性能。
- 更高的效率: 渐进式训练策略避免了在训练过程中直接使用高分辨率和长时间的视频,从而降低了训练成本和时间。
🚀 总体任务描述
Pick-&-Place. Closed-loop robot execution of V-JEPA 2-AC for multi-goal pick-&-place tasks.
- 任务是一个典型的机器人任务:“抓取与放置”(Pick & Place)。
- 使用了 V-JEPA 2-AC 模型,并以 闭环(closed-loop)方式 控制机器人执行任务。
- 闭环意味着:模型会不断地根据当前感知结果 实时规划动作,而不是一开始就规划好所有动作(开环控制)。
🧭 多阶段目标切换逻辑
Highlighted frames indicate when the model achieves a sub-goal and switches to the next goal.
- 模型会按照预设的 多个子目标(sub-goals) 分阶段执行任务。
- 当模型检测到当前子目标达成时,它会 自动切换到下一个子目标。
- “Highlighted frames” 指的是图示或视频中的高亮帧,用来可视化子目标之间的切换时机。
🧱 三个目标阶段
The first goal image shows the object being grasped, the second goal image shows the object in the vicinity of the desired location, and the third goal image shows the object placed in the desired position.
- 整个任务被拆分为三个子目标,分别表示任务的三个阶段:
- 第一个目标图像:物体被机器人成功抓取;
- 第二个目标图像:物体被移动到接近目标区域;
- 第三个目标图像:物体被准确地放置在指定位置。
⏱ 时间分配与目标切换
The model first optimizes actions with respect to the first sub-goal for 4 time-steps before automatically switching to the second sub-goal for the next 10 time-steps, and finally the third goal for the last 4 time-steps.
- 模型按照时间顺序对各阶段进行控制:
- 前4步:专注于实现第一个目标(抓取);
- 接下来的10步:执行移动任务(靠近目标位置);
- 最后4步:完成最终放置;
- 这种结构可以看作是一个分阶段的规划控制策略。
🎯 目标条件规划(goal-conditioned planning)
Robot actions are inferred through goal-conditioned planning.
- 动作不是直接预测出来的,而是通过“目标条件规划(goal-conditioned planning)”得到的:
- 模型在每个阶段根据当前状态 + 当前目标图像,预测未来的最优动作序列;
- 这种方法更具通用性和泛化能力(可以面对新的目标图像)。
🧪 零样本泛化能力
The V-JEPA 2-AC model is able to perform zero-shot pick-&-place tasks on two Franka arms in different labs, with various object configurations and cluttered environments.
- V-JEPA 2-AC 展现出强大的零样本能力(zero-shot):
- 无需在当前环境/物体配置下进行额外训练或微调;
- 能够在 两个不同实验室的 Franka Panda 机械臂上完成任务;
- 并且环境中可能存在大量 干扰(clutter)和不同物体排布(object configurations),但模型仍然能成功完成任务。
总结一下文章的贡献
1. 自监督视频模型: V-JEPA2 通过自监督学习,利用互联网规模的视频数据和少量机器人交互数据,构建了强大的视频模型,实现了对世界的理解、预测和规划。[3][9][12]
- 理解: V-JEPA2 在运动理解和外观识别等任务上取得了最先进的性能,例如在 Something-Something v2 上达到了 77.3% 的 top-1 准确率。[90-92]
- 预测: V-JEPA2 在人类动作预测任务上也取得了最先进的性能,例如在 Epic-Kitchens-100 上达到了 39.7 的 recall-at-5。[14]
- 规划: V-JEPA2-AC 模型通过利用少量机器人交互数据,实现了零样本抓取和放置任务,证明了其在机器人控制领域的潜力。[12][14][63]
2. 渐进式训练: V-JEPA2 采用了一种渐进式训练策略,逐步增加输入视频的时间和空间分辨率,从而提高了模型的性能和效率。[39-40][150]
3. 潜在空间世界模型: V-JEPA2-AC 模型利用潜在空间世界模型,能够理解环境动态,预测未来状态,并进行规划,从而实现机器人控制。[45][48][60]
4. 视频问答: V-JEPA2 与大型语言模型结合,在多个视频问答任务上取得了最先进的性能,证明了其在视频内容理解方面的潜力。[109-110]
总而言之,V-JEPA2 是一个强大的视频模型,它通过自监督学习和潜在空间世界模型,实现了对世界的理解、预测和规划,为开发更先进的 AI 系统奠定了基础。